11. ネットワーク

ネットワーキングと Linux とはほとんど同義語である。本当の意味で、Linux は インターネットもしくは World Wide Web(WWW) の産物である。開発者やユーザたち はウェブを使って情報やアイデアやコードを交換しているし、Linux そのものが組織に おけるネットワークへの要求を満たすために利用されている。この章では、TCP/IP と 総称されるネットワークプロトコルを Linux がどのようにサポートしているかを 解説する。
TCP/IP プロトコルが設計されたのは、ARPANET に接続されたコンピュータ間 での通信をサポートするためであった。合衆国政府によって設立されたアメリカ の研究用ネットワークである ARPANET は、ネットワークの基本概念を作り出した パイオニアであり、その中には、パケットスイッチング(packet switching)や、ある プロトコルが別のプロトコルのサービスを利用するというプロトコル層(protocol layer)といった概念がある。 ARPANET は 1988 年に解散されたが、その後継者(NSF( 脚注 1) NET やインターネット)はそれ以上のものに成長した。 今日 World Wide Web と呼ばれるものは、ARPANET から発展しており、それ自体が TCP/IP プロトコルによってサポートされている。Unix は ARPANET 上で広範囲に 使用されが、最初にリリースされたネットワークバージョンの Unix は 4.3 BSD であった。Linux におけるネットワークの実装は、(いくつかの拡張機能とともに)BSD ソケットと TCP/IP 全般をサポートしている点で、4.3 BSD をモデルとするものであ る。BSD ソケットというプログラミングインターフェイスが 採用されたのは、その人気ゆえであり、Linux とその他の Unix プラットフォーム間 でのアプリケーションの移植を容易にするためであった。
11.1 TCP/IP ネットワーキングの概要
この章では、TCP/IP ネットワーキングにおける基本原則を概説する。 しかし、本書のテーマからして、徹底した記述というわけではない。 IP ネットワークでは、すべてのマシンが IP アドレスを割り当てられる。これはマシン をユニークに識別する 32 ビットの数である。WWW は広大で今も成長過程にあり、そ れに接続された IP ネットワークとすべてのマシンはユニークな IP アドレスを割り当 てられなければならない。 IP アドレスは、たとえば 16.42.0.9 のようにドットで区切られた 4 つの 数字で表現される。この IP アドレスは実際には、ネットワークアドレスとホスト アドレスのふたつの部分に分かれる。( IP アドレスにはいくつかのクラスがあるので) それらの部分のサイズは定まっていないが、仮に 16.42.0.9 を例に取り、ネットワー クアドレスを 16.42 とし、ホストアドレスを 0.9 であるとする。ホストアドレスは さらにサブネットとホストアドレスとに再分割できる。ここでも 16.42.0.9 を例に 取ると、サブネットアドレスは 16.42.0 であり、ホストアドレスは 9 となるだろう。 IP アドレスの細分化により、組織はネットワークを再分割できる。 たとえば、16.42 が ACME コンピュータ会社のネットワークアドレスであるとすると、 16.42.0 はサブネット 0 であり、16.42.1 はサブネット 1 となる。これらのサブ ネットは、異なる建物の中にあり、おそらく専用線かもしくは無線によっ て接続されているだろう。IP アドレスはネットワーク管理者によって割り当てられる ので、IP サブネットを持つことはネットワーク管理を分散するよい方法である。IP サブネットの管理者は、その IP サブネットワーク内で自由に IP アドレスを割り当 てることができるからである。
しかし、一般的に IP アドレスは覚えるのがやや困難である。名前のほうがより
簡単であり、linux.acme.com のほうが 16.42.0.9 よりもずっと覚えやすい。だが、
ネットワーク名を IP アドレスに変換するには多少の仕組みが必要となる。そうした
名前は、/etc/hosts ファイル内で静的に指定できるが、Linux は、
DNS (Domain Name System) サーバに問い合わせて、名前を IP アドレスに
変換することもできる。その場合、ローカルホストはひとつ以上の DNS サーバの IP
アドレスを知る必要があり、それは /etc/resolv.conf で指定される。
ウェブページを読む時などに他のマシンに接続する際はいつも、相手のマシンとの データ交換に IP アドレスが使用される。このデータは IP パケットに含まれていて、 個々のパケットは、送信元の IP アドレスと送信先の IP アドレス、チェックサム その他の情報を含んだ IP ヘッダを持っている。チェックサムは IP パケットの データから導き出されるもので、それによって、おそらく電話回線上のノイズなどで、 転送中に IP パケットが壊れなかったかどうかを IP パケットの受信者が判断できる ようになる。アプリケーションによって送信されるデータは、処理しやすいように、 より小さなパケットへと分割される。IP データパケットのサイズは接続 メディアによって異なり、イーサネットパケットは一般に PPP パケットよりも サイズが大きい。送信先のホストはそのデータパケットを組み立て直して、それを受信 すべきアプリケーションに渡さなければならない。多くのグラフィックイメージを 含むウェブページに比較的低速なシリアル回線経由でアクセスする場合、このデータ の分割と統合の過程を視覚的に理解することができる。
同一の IP サブネットに接続されたホスト間ではお互いに直接 IP パケットを送信 することができるが、それ以外のすべてのパケットは特別なホストであるゲートウェイ (gateway)に送信される。ゲートウェイ(あるいはルータ(router))は、複数の IP サブネットに接続されていて、あるサブネット上で受信した IP パケットが、別のサブ ネット宛であった場合に、その IP パケットを送信先に向けて送りなおす。 たとえば、サブネット 16.42.1.0 と 16.42.0.0 がゲートウェイに よって接続されている場合、サブネット 0 からサブネット 1 へと送信されるパケット は、ルーティングが可能なゲートウェイに送られなければならない。ローカルホスト はルーティングテーブルを設定し、それによって正しいマシンに IP パケットを 経路付けすることができる。すべての IP の送信先に関して、ルーティングテーブル 内にひとつのエントリがある。Linux は、それを参照することで、どのホストに送れば よいかを判断して、IP パケットを宛先に届けている。 これらのルーティングテーブルは、複数のアプリケーションがネットワークを使用した り、ネットワークトポロジーが変更された場合など、時間の経過によって動的に変化す る。
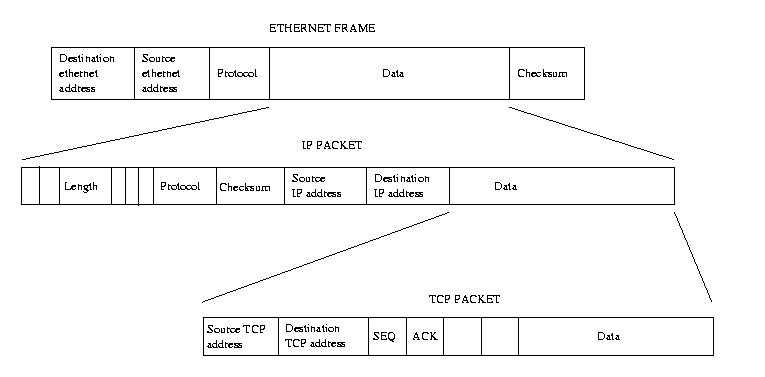
図表(10.1) TCP/IP プロトコル層
IP(Internet Protocol) プロトコルは、他のプロトコルがデータを運ぶために利用
する、転送のための層(layer)である。TCP (Transmission Control Protocol)は、エン
ドシステム間における信頼性のあるプロトコルで、自己のパケットを送受信するために
IP を使用する。
IP が独自のヘッダを持つように、TCP も独自のヘッダを持つ。TCP はコネクション
(connection)に基づくプロトコルなので、両端のアプリケーションは、間に多くの
サブネットワークやゲートウェイ、ルータがある場合でも、単一の仮想的コネクション
によって接続される。TCP はふたつのアプリケーション間で信頼性をもってデータ
の受け渡しを行うので、データの喪失や重複が生じないことが保証される。TCP が IP
を利用してパケットを転送するとき、IP パケット内に含まれるデータは TCP パケット
そのものである。
個々の通信ホスト上で IP 層は、IP パケットの送受信に関して責任を持つ。
UDP (User Datagram Protocol)も IP 層を使用して自分のパケットを転送するが、
TCP と異なり、UDP は信頼性のあるプロトコルではなく、単にデータグラム(datagram)
サービスを提供するだけである。
このように、IP は、他のプロトコルによって利用されている。したがって、IP パケッ
トを受け取った際、受信した IP 層は、どの上位プロトコル層に対してその IP パケッ
トに含まれるデータを渡すべきか認識できなければならない。これを簡単に実現するた
めに、すべての IP ヘッダには、プロトコル識別子が記述された 1 バイトの情報があ
る。TCP が IP 層に IP パケットの送信を依頼するとき、IP パケットのヘッダには、
そのパケットが TCP パケットを含むものであることを伝える情報が記述される。
受信した IP 層は、そのプロトコル識別子を使用して、どの上位層(この場合は、
TCP)に受信したデータを渡すべきかを判断する。
また、アプリケーションが TCP/IP 経由で通信を行うとき、それらは相手方の IP アド
レスだけでなく、アプリケーションのポート番号をも指定しなければならない。
ポート番号はアプリケーションをユニークに特定するものであり、標準的なネット
ワークアプリケーションは標準のポート番号を使用する。たとえば、ウェブサーバは
80 番ポートを使用している。これら登録済みのポート番号は、/etc/services ファイルで確認できる。
このようなプロトコルの多層構造は、TCP, UDP や IP だけに留まらない。すなわ ち、IP プロトコル自身が様々な異なる物理メディアを使用して IP パケットを他の IP ホストに転送している。したがって、それらの物理メディア自体も独自のプロトコル ヘッダを付け加えている。イーサネット層がその一例であり、他にも PPP 層や SLIP 層 などがある。イーサネットのネットワークでは、多くのホストを同時に単一の物理ケー ブルに接続することが可能である(訳注: 10BASE5 など。現在、単一の物理ケーブルが 使われることは少なくなりました)。送信されたイーサネットフレーム(frame)は、その ケーブルに接続されたすべてのホストから見ることが出来るので、個々のイーサネット デバイスはユニークな(ハードウェア)アドレスを持たなければならない。 特定の(ハードウェア)アドレスに対して送信されたイーサネットフレームはそのアドレ スのホストに受信され、ネットワークに接続されたそれ以外のすべてのホストからは無 視される。こうしたユニークなアドレスはイーサネットデバイスの製造時にデバイスに 組み込まれていて、通常、イーサネットカードの SROM( 脚注2) に保存されている。 イーサネットのアドレスは 6 バイト長で、たとえば、08-00-2B-00-49-A4 といったもの になっている。イーサネットのアドレスにはマルチキャスト( 訳注: 用語集(multicast))の目的に予約されたものがあり、そうした送信先 アドレスを設定されて送信されたイーサネットフレームは、そのネットワーク上のすべ てのホストで受信される。 イーサネットフレームは、多種のプロトコルを(データとして)運ぶことができるので、 IP パケットの場合と同様に、イーサネットフレームのヘッダにはプロトコル識別子が 含まれている。これによって、イーサネット層は IP パケットを正確に受信して、それ を IP 層に渡すことができる。
イーサネットのような(ケーブルに繋がったすべてのホストにフレームが流れる) マルチコネクションのプロトコル経由で IP パケットを送信するためには、IP 層は、 IP ホストのイーサネットアドレスを知らなければならない。というのも、IP アドレス は単にアドレス割り当ての概念にすぎず、イーサネットデバイス自体が独自の物理 アドレスを持っているからである。すなわち、IP アドレスはネットワーク管理者の 意志によって割り当てや再割り当てが可能であるのだが、ネットワークハードウェア は、自分の物理アドレスが付加されたイーサネットフレームか、あるいはすべての マシンで受信すべき特別なマルチキャストアドレスにしか反応しないからである。 Linux は、ARP (Address Resolution Protocol)を使用して、マシンが、IP アドレスを イーサネットアドレスのような実際のハードウェアアドレスに変換できるようにしてい る。 ある IP アドレスに関連付けられたハードウェアアドレスを知ろうとするホストは、 変換したい IP アドレスを含めた ARP リクエストパケットを、マルチキャストアドレス を付けてネットワーク上のすべてのノード(node)に送信する。その IP アドレスを持つ ターゲットホスト(target host)は、自分の物理アドレスを含めた ARP リプライによっ てそれに応答する。ARP はイーサネットデバイスだけでしか利用できないわけではな く、 FDDI などのそれ以外の物理メディアに対しても IP アド レスの解決が可能である。 ARP が利用できないネットワークデバイスはそれが出来ない旨マークされているので、 その場合、Linux がARP を試すことはない。ARP の逆の機能も存在しており、リバース ARP もしくは RARP は、ハードウェアアドレスを IP アドレスに変換する。これは ゲートウェイによって利用されるもので、ゲートウェイは、リモートネットワークにあ る IP アドレスが書かれた ARP リクエストに応答する際にそれを使用する。
11.2 Linux の TCP/IP ネットワーク層

図表(10.2) Linux のネットワーク層
ネットワークプロトコル自体が多層構造を持つのと同様に、図表(10.2)では、Linux
がインターネットプロトコルアドレスファミリ(address family)をソフトウェアの多層
構造として実装していることが示されている。BSD ソケットは、BSD ソケットだけに関
する汎用のソケット管理ソフトウェアとしてサポートされている。
BSD ソケットをサポートするのが INET ソケット層で、これは、IP ベースの TCP や
UDP プロトコルのためのエンドポイント通信を管理する。
UDP(User Datagram Protocol)はコネクション管理を行わないプロトコル
であるが、TCP(Transmission Control Protocol)は信頼性のある一対一(end to end)の
プロトコルである。UDP パケットが送信されるとき、Linux はそれが安全に送信先に
届いたかどうか分からないし、気にもしない。TCP パケットは番号付けされている
ので、TCP コネクションの両方のエンド(end, 端)は、送信されたデータが正しく受信さ
れたかどうかを確認できる。
IP 層には、インターネットプロトコル(IP)を処理するためのコードが含まれている。
このコードは、受信したデータの IP ヘッダを取得し、その IP パケットが TCP か
UDP のどちらかの上位層に宛てたものかを判断して、適切な上位層にルーティングす
る。IP 層の下で Linux のネットワーキングをサポートしているのが、PPP やイーサ
ネットといったネットワークデバイスである。ネットワークデバイスとは必ずしも物理
デバイスを意味するものではない。ループバックデバイス(loopback device)などは純粋
なソフトウェアデバイスだからである。
mknod で作成される Linux の標準的なデバイスファイルとは異なり、ネット
ワークデバイスはその基礎となるソフトウェアが物理デバイスを検出し初期化した場合
にだけ現れる。
カーネルに適切なイーサネットデバイスドライバを組み込んだ場合のみ、/dev/eth0 を見ることができる。ARP プロトコルは、IP 層と ハードウェア
アドレス解決のために ARP をサポートする下位のプロトコルとの間に位置している。
11.3 BSD ソケットインターフェイス
BSD ソケットインターフェイスは、汎用インターフェイスであり、ネットワークの 様々な形態をサポートするだけでなく、プロセス間通信の仕組みでもある。 ソケットは通信リンクの一方のエンド(end, 端)を記述するもので、ふたつの通信プロセ スが個別にソケットを持ち、両者の間の通信リンクのそれぞれのエンドを記述する。 ソケットはパイプの特殊なケースであると考えることも可能だが、パイプと異なり、 ソケットは保持できるデータ容量に制限がない。Linux は、いくつかのソケットクラス (socket class)をサポートしており、それらはアドレスファミリ(address family)と 呼ばれている。これは、個々のクラスが独自の通信方式を持っているからである。 Linux は次のようなアドレスファミリもしくはドメイン(domain)をサポートしている。
- UNIX
Unix ドメインソケット。
- INET
インターネットアドレスファミリ(internet address family)は、 TCP/IP 経由の通信をサポートしている。
- AX25
アマチュア無線 X25。
- IPX
Novell IPX。
- APPLETALK
Appletalk DDP
- X25
X25。
アドレスファミリもしくはドメインには、いくつかのソケットタイプ(socket type) があり、それらはコネクションをサポートするサービスのタイプを表している。 すべてのサービスタイプをサポートしていないアドレスファミリもある。 Linux BSD ソケットは次のいくつかのソケットタイプをサポートしている。
- Stream
このソケットは、双方向で順次送達確認の行われる信頼性のあるデータストリーム (data stream)であり、通信途上でのデータの喪失や破壊、複製が生じないよう保証され たものである。Stream ソケットは、インターネット(INET)アドレスファミリの TCP プロトコルによってサポートされている。
- Datagram
このソケットは、双方向でのデータ通信を提供するが、stream ソケットと異なり、 メッセージが到達する保証はない。到達した場合でも、順番通り届いたか、さらに 複製や破壊はないかといったことは保証されない。このタイプのソケットは、インター ネットアドレスファミリの UDP プロトコルによってサポートされている。
- Raw
これは、プロセスが、下位層のプロトコルに直接(それゆえ、生(raw))アクセスする ものである。これを使うと、たとえば、raw ソケットをイーサネットデバイスに対して オープンし、生(raw)の IP データトラフィックを見ることが可能になる。
- Reliable Delivered Messages
これは、datagram ソケットと非常に類似しているが、データの到着は保証される。
- Sequenced Packets
これは、データパケットサイズが固定されていることを除いて、stream パケットと 同じである。
- Packet
これは、標準的な BSD ソケットタイプではない。Linux 固有の拡張であり、 これを使うと、プロセスがデバイスレベルで直接パケットにアクセスできる。
ソケットを利用して通信を行うプロセスは、クライアントサーバモデル(client
server model)を使用する。
サーバはサービスを提供し、クライアントがそのサービスを利用する。その典型が
ウェブサーバであり、サーバがウェブページを提供し、クライアント、もしくは
ブラウザがそのページを読み出す。ソケットを使うサーバは、まずソケットを作成
し、それに名前を結びつける(bind)。その名前のフォーマットはそのソケットの
アドレスファミリに依存し、事実上サーバのローカルアドレスになる。ソケットの
名前もしくはアドレスは、
sockaddr データ
構造体を使って指定される。
INET ソケットは、IP ポート番号をそれに結びつける。登録済みポート番号は、
/etc/services ファイルで見ることができる。たとえば、ウェブサーバのポー
ト番号は 80 である。アドレスをソケットに結びつけたら、サーバは、そのアドレス
を指定したコネクションリクエストが来るまで待機(listen)している。リクエストの
発信者である
クライアントはソケットを作成し、サーバのターゲットアドレスを指定して、
ソケット上でコネクションリクエストを出す。INET ソケットの場合、サーバの
アドレスは、その IP アドレスとポート番号である。入って来たリクエストは、
様々なプロトコル層を
上昇して、サーバの待機中(listening)のソケット上で(処理されるのを)待つ。サーバ
が入って来たリクエストを受信した場合、サーバは、それを受け入れる(accept)か拒絶
するかのいずれかを行う。リクエストが受け入れられる場合、サーバは
受け入れるための新しいソケットを作成しなければならない。入って来るコネクション
リクエストのために、いったん待機状態(listening)に入ったソケットは、
コネクションをサポートするために使用することはできない。
コネクションが確立されたら、両者は自由にデータの送受信ができる。最後に、それ以
上コネクションが必要なくなったとき、コネクションは遮断(shutdown)できる。
その際、転送中のデータパケットがあっても正しく処理されるよう注意を払う
必要がある。
BSD ソケット上での操作が厳密に何を意味するかは、その基礎となるアドレス ファミリによって異なる。TCP/IP コネクションの設定は、アマチュア無線 X.25 コネクションの設定とは非常に異なる。仮想ファイルシステムの場合のように、Linux は、BSD ソケット層(layer)を使ってソケットインターフェイスを抽象化している。 BSD ソケット層側は、アプリケーションプログラムに対する BSD ソケットインター フェイスと関係付けられ、アプリケーション側は、アドレスファミリごとに独立した 固有のソフトウェアによりサポートされている。 カーネルに組み込まれたアドレスファミリは、カーネルの初期化時に、BSD ソケット インターフェイスと伴に登録される。その後、アプリケーションが BSD ソケットを 作成して使用する場合、BSD ソケットとそれがサポートするアドレスファミリとの 間で関連付けがなされる。この関連付けは、データ構造体とアドレスファミリ固有の サポートルーチンとをクロスリンクすることにより実現される。 たとえば、アドレスファミリ固有のソケット作成ルーチンがある場合、アプリケー ションが新規にソケットを作成しようとする際には、BSD ソケットインターフェイス は、そのルーチンを使用してソケットを作成する。
一般に、カーネル設定の際には、いくつものアドレスファミリとプロトコルが
ビルドされ、
protocols 配列に組み込まれる。それらはそれぞれ、INET といった名前
とその初期化ルーチンのアドレスとによって表現される。ブート時にソケット
インターフェイスが初期化されるとき、個々のプロトコル初期化ルーチンが呼び出さ
れる。ソケットアドレスファミリにとって、これは、一組のプロトコル操作
を登録することを意味する。これは、一組のルーチンであり、それぞれが
アドレスファミリ固有のプロトコル操作を実行する。登録されたプロトコル操作
ルーチンは、
pops 配列に保存されるが、
それは
proto_ops
データ構造体へのポインタの配列である。
[see:
include/linux/net.h]
proto_ops データ構造体は、アドレスファミリタイプと、アドレス
ファミリ固有のソケット操作ルーチンに対する一連のポインタから構成されている。
pops 配列は、アドレスファミリ識別子によるインデックスが
付けられていて、たとえば、インターネットアドレスファミリの識別子(AF_INET)は
2 である。
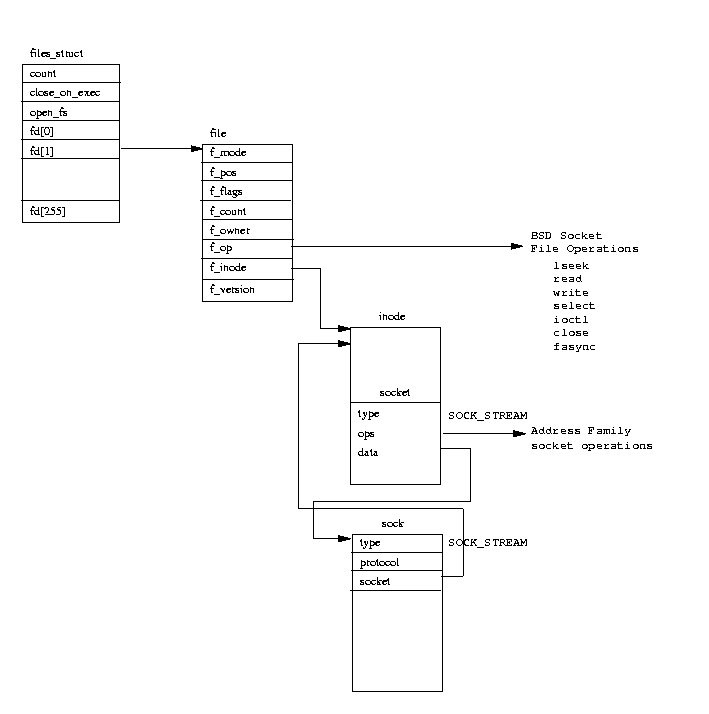
図表(10.3) Linux BSD ソケットデータ構造体
11.4 INET ソケット層
INET ソケット層は、TCP/IP を含むインターネットアドレスファミリをサポート
するものである。上記で説明したように、これらのプロトコルは多層構造になってい
て、ひとつのプロトコルが別のプロトコルのサービスを利用する。
Linux の TCP/IP のコードとデータ構造はその多層構造を反映している。BSD ソケット
層に対する INET ソケット層のインターフェイスは、一連のインターネットアドレス
ファミリのソケット操作ルーチンを経由するものであり、Linux は、ネットワークの
初期化時にそれらのルーチンを BSD ソケット層と伴に登録する。
それらは、登録された他のアドレスファミリと一緒に
pops 配列に保存される。BSD ソケット層は、登録済みの INET
proto_ops データ構造体から、INET 層ソケットを
サポートするルーチンを呼び出して操作を実行する。
たとえば、アドレスファミリを INET と指定した BSD ソケット作成リクエストは、
その基礎にある INET ソケット作成関数を使用する。
BSD ソケット層は、それらの個々の操作をする際に、BSD ソケットを
表す
socket データ構造体を INET 層に渡す。
BSD ソケットが TCP/IP 固有の情報でごちゃごちゃにならないように、INET ソケット
層は、独自のデータ構造体である
sock を使用し、
この構造体を BSD ソケット層の socket データ構造体にリンクする。
[see:
include/net/sock.h]
このリンク関係は、図表(10.3)で示されている。
INET ソケット層は sock データ構造体を BSD socket データ構造体
にリンクする際、BSD socket の dataポインタを使用する。
これは、それ以降の INET ソケットの呼び出しで、簡単に sock データ構造体
が取り出せることを意味する。
sock データ構造体のプロトコル操作ルーチンへのポインタは、その構造体
作成時に設定されるが、設定の内容はリクエストされたプロトコルによって異なる。
TCP/IP がリクエストされた場合、sock データ構造体のプロトコル操作ルーチ
ンへのポインタは、TCP コネクションに必要な TCP プロトコル操作ルーチンのセットを
ポイントする。
BSD ソケットの作成
システムコールで新規ソケットを作成する際は、アドレスファミリ、ソケットタイ
プ、プロトコルに関する識別子を渡す。
[see: sys_socket(), in
net/socket.c]
まず、リクエストされたアドレスファミリを使って、
pops 配列内に合致するアドレスファミリがあるかどうか検索される。
たとえば、特定のアドレスファミリがカーネルモジュールとして実装されている場合
は、処理を継続する前に kerneld デーモンによって該当するモジュール
がロードされることになる。
新規の
socket データ構造体が割り当てられて、
BSD ソケットが表現される。
実際、socket データ構造体は、物理的には VFS
inode データ構造体の一部なので、socket の割り当ては、
VFS inode の割り当てを意味する。
これは奇妙に思われるかもしれないが、ソケットは、通常ファイルの操作と同じ方法で
操作され得ることを考えてほしい。すべてのファイルが VFS inode データ
構造体によって表現されるので、ファイル操作をサポートするには、BSD ソケットは
VFS inode データ構造体によっても表現されなければならないのである。
新規に作成された BSD
socket データ構造体に
は、アドレスファミリ固有のソケットルーチンへのポインタが含まれていて、このルー
チンは、
pops 配列から取り出された
proto_ops データ構造体に設定される。そのタイプ
は、リクエストされたソケットタイプ、すなわち SOCK_STREAM,
SOCK_DGRAM 等に設定される。アドレスファミリ固有の作成ルーチンは、proto_ops データ構造体に保存されたアドレスを使用して呼び出される。
未使用のファイル記述子が、カレントプロセスの
fd 配列から割り当てられて、それがポイントする
file データ構造体が初期化される。
この際に同時に為される処理として、そのファイル操作ポインタのポイント先が、
BSD ソケットインターフェイスによってサポートされる BSD ソケットファイル操作
ルーチン群へと設定される。それ以後の何らかの操作は、ソケットインターフェイス
へと誘導され、ソケットインターフェイスがさらにアドレスファミリ操作ルーチンを
呼び出すことで、それがサポートするアドレスファミリへと誘導される。
アドレスを INET BSD ソケットに bind する
入って来るインターネットコネクションリクエストを待機(listen)するためには、
個々のサーバが INET BSD ソケットを作成して、それにアドレスを結びつけ(bind)
なければ
ならない。bind 操作の大部分は、その基礎にある TCP と UDP プロトコル層の
サポートを受けた INET ソケット層内部で処理される。アドレスを結びつけ(bind)ら
れた
ソケットは、それ以外の通信には使用できない。これは、ソケットの状態(state)が
TCP_CLOSE でなければならないことを意味する。
sockaddr 構造体から bind 操作ルーチンに渡される情報の中には、
結びつけ(bind)られるべき IP アドレスと、オプションとしてポート番号がある。
通常、bind された IP アドレスは、ネットワークデバイスに割り当てられたもので
あり、そのデバイスは INET アドレスファミリをサポートするもので、そのデバイス
のインターフェイスは起動されていて使用可能でなければならない。そのインターフェ
イスが現在アクティブであるかを確認するには、ifconfig コマンドを使用す
ればよい。
IP アドレスは、アドレス(のビット)をすべて 1 にするか、すべて 0 にするかい
ずれかによって、IP ブロードキャストアドレス(
訳注:broadcast address)にすることもできる。
それは特別なアドレスで、「全員に送信」(
脚注3)することを意味する。
マシンが透過的なプロキシかファイアウォールである場合、IP アドレスの指定を任意
の IP アドレスとしても構わないが、スーパーユーザの権限を持ったプロセスだけが任
意の IP アドレスを結びつけ(bind)できる。結びつけ(bind)られた IP アドレスは
sock データ構造体の recv_addr(訳注:
recv_saddr?) と
saddr
に保存される。それらは、ハッシュへの問い合わせの際と、IP アドレスを互いに送信
しあう場合に使用される。ポート番号はオプションであり、指定されない場合、
サポートするネットワークに未使用の番号を割り当てるよう要請がなされる。
慣習では、1024 未満のポート番号は、スーパーユーザの特権がない
プロセスでは使用できない。基礎となるネットワークがポート番号を割り当てる場合、
1024 以上の番号を常に割り当てる。
パケットが基礎となるネットワークデバイスで受信されると、パケットは正しい
INET ソケットと BSD ソケットへと伝達されて、処理されなければならない。
そのために、UDP と TCP は、ハッシュテーブルを管理していて、それを使って、到着
した IP パケット内にあるアドレスを問い合わせて、正しい socket/sock ペアへと IP パケットを伝達する。TCP はコネクション指向の
プロトコルなので、UDP パケットの場合よりも TCP パケットを処理する場合のほうが
関係する情報量が多い。
UDP は、割り当てられた UDP ポートを
udp_hash というハッシュテーブルで管理している。
そのハッシュテーブルは、
sock データ構造体への
ポインタから構成されていて、sock 構造体はポート番号に基づいてハッシュ
関数によりインデックス付けされている。UDP のハッシュテーブルは、持ち得るポート
番号の数よりも小さい(udp_hash は 128 か、UDP_HTABLE_SIZE の数のエント
リしか持たない)ので、テーブル内のエントリのなかには、個々の sock が
次へのポインタを持つことでリンクされた sock データ構造体の連結リスト
をポイントしているものがある。
TCP は、複数のハッシュテーブルを管理しているので、UDP よりずっと複雑である。
しかし、TCP は、bind 操作をする間、実際に bind すべき
sock データ構造体をそのハッシュテーブルに付け加えるわけではなく、
要求されたポート番号が現在使用されていないかどうかチェックするだけである。
sock データ構造体は、listen 操作の間に TCP のハッシュテーブルに付け加
えられる。
REVIEW NOTE: What about the route entered?
INET BSD ソケット上でコネクションを確立する
ソケットが作成されると、そのソケットは、相手側からの(inbound)コネクション リクエストを待機(listen)するために使用されていない限り、自己側からの(outbound) コネクションリクエストのために使用できる。 UDP のようなコネクションレスのプロトコルの場合、このソケット操作は限定された 意味しか持たないのだが、TCP のようなコネクション指向のプロトコルの場合だと、 それはふたつのアプリケーション間で仮想サーキットを構築することを意味する。
自己側からの(outbound)コネクションリクエストが可能となるのは、INET BSD
ソケットを使用し、しかも使用する INET BSD ソケットが適切な状態(state)にある
場合だけである。
すなわち、そのソケット上で既にコネクションが確立していないこと、およびそれが
相手側からの(inbound)コネクションリクエストの待機のために使用されていない
場合である。
これは、BSD
socket データ構造体が
SS_UNCONNECTED の状態になければならないことを意味する。
UDP プロトコルはアプリケーション間で仮想コネクションを確立することはなく、送信
されたメッセージはすべてデータグラム(datagram)であるので、送信メッセージが送信
先に届くかどうかは確定しない。しかし、UDP に関しても BSD ソケット操作である
connect はサポートされている。UDP INET BSD ソケット上での connect 操作は、
単にリモー
トアプリケーションのアドレスとして、その IP アドレスと IP ポート番号を設定
する。さらに、ルーティングテーブルのエントリのキャッシュを設定して、(当該ルート
が無効とならない限り)その BSD ソケットから送信された UDP パケットが再度ルーティ
ング情報をチェックする必要がないようにする。キャッシュされたルーティング情報
は、INET
sock データ構造体内の
ip_route_cache ポインタによってポイントされる。
アドレス情報が指定されない場合、このキャッシュされたルーティング情報と IP アド
レス情報が、その BSD ソケットを使って送信されるメッセージのために
自動的に使用される。そして、UDP は sock の状態(state)を
TCP_ESTABLISHE に変更する。
TCP BSD ソケット上での connect 操作の場合、TCP は、コネクション情報を含んだ
TCP セグメント(segment)を作成して、指定された IP 送信先に送らなければならない。
TCP セグメントには、コネクション情報、開始セグメントのシーケンス番号(sequence
number)、接続を開始したホスト側が処理できるセグメントの最大サイズ(maximum
segment size, MSS)、送信および受信の際のウィンドウサイズ(window size)、等が含
まれる。
TCP では、すべてのセグメントに番号が付けられるので、シーケンス番号の初期値に
は、最初のセグメントの番号が利用される。Linux は、悪意のあるアタックを防ぐため
に、妥当な範囲の乱数値を選択している。TCP コネクションの一方から送信され、相手
側で問題なく受信されたセグメントに対してはすべて、データ破損なく成功裡に到達し
た旨の送達確認(acknowledgement)がなされる。送達確認のないセグメントは再送され
る。送信と受信のウィンドウサイズとは、送達確認が送信されないまま存在しうる未解
決セグメントの数である。最大セグメントサイズは、コネクションリクエストを発信し
た側で使用されているネットワークデバイスに依存する。受信側のネットワークデバイ
スがそれよりも小さい最大セグメントサイズしかサポートしていない場合、そのコネク
ションは小さい方を使用する。
自己側からの(outbound) TCP コネクションリクエストを発したアプリケーションは、
相手側アプリケーションがコネクションリクエストを受け入れ(accept)るか拒絶(
reject)するかを返答してくるまで待たなければならない。
その場合、TCP ソケットは相手側からのメッセージを期待しているので、そのソケット
は
tcp_listening_hash に加えられ
て、それによって、相手側からの TCP セグメントはその
sock データ構造体へと誘導される。また、TCP はタイマーをスタート
させて、送信先のアプリケーションがリクエストに対して応答しない場合、自己側から
の(outbound)コネクションリクエストをタイムアウトさせる。
INET BSD ソケット上での待機(listen)
ソケットにアドレスが結びつけ(bind)られると、そのソケットは、結びつけ(bind) られたアドレスを指定した入ってくるコネクションリクエストを待機する(listen)。 ネットワークアプリケーションは、予めソケットにアドレスを結びつけ(bind)なくて もそのソケット上で待つことができる。 その場合、INET ソケット層が(そのプロトコルに関して)未使用なポート番号を探して、 自動的にそのソケットに結びつけ(bind)る。ソケット関数 listen は、ソケット状態 (state)を TCP_LISTEN 状態へと変更し、入って来る接続を許可するために必要とされ るそのネットワーク固有のすべての処理を行う。
UDP ソケットの場合、ソケット状態の変更で充分だが、TCP は、その際、アクティ
ブとなったことで、ソケットの
sock データ構造体
をふたつのハッシュテーブルに付け加えなければならない。
それらは、
tcp_bound_hash テーブル
と
tcp_listening_hash である。
どちらも、IP ポート番号に基づくハッシュ関数を経由して、インデックス付けされる。
入って来る(incoming) TCP コネクションリクエストがアクティブな待機中
(listening)のソケットで受信されたときはいつも、TCP は、それを表す新規の
sock データ構造体を作成する。
この sock データ構造体は、コネクションリクエストが最終的に受け入れ
(accept)られ
たときに、TCP コネクションのボトムハーフ(bottom half)となる。また TCP は、
入って来たコネクションリクエストを含む
sk_buff を複製(cloning)して、それを、待機(listen)状態
の sockデータ構造体の
receive_queue
キューに登録する。
複製された sk_buff 構造体には、新規に作成された sock 構造体
へのポインタが含まれる。
コネクション要求を受け入れる(accept)
UDP はコネクションの概念をサポートしていないので、INET ソケット上でのコネク
ションリクエストの受け入れ(accept)は、TCP プロトコルだけに適用される。先ず、
待機(listen)状態のソケット上の accept 操作ルーチンは、その
socket データ構造体から、新規の socket データ
構造体を複製する。
次に accept 操作ルーチンは、入って来る(incoming)コネクションリクエストを受け入
れる(accept)ために、サポートするプロトコル層(layer)、すなわちこの場合 INET 層に
渡される。
INET プロトコル層は、その下位層のプロトコルがコネクションをサポートしていない
場合、たとえば UDP であった場合は、受け入れ(accept)操作に失敗する。
下位層がコネクションをサポートしている場合、accept 操作ルーチンは、実(real)
プロトコル(この場合、TCP)へと渡される。
accept 操作は、ブロックするかしないかのいずれかで行える。
ブロックしない場合で、受け入れるべきコネクションがない場合、accept 操作ルーチン
は失敗し、新規に作成された socket データ構造体は破棄される。
ブロックする場合、accept 操作ルーチンを実行しているネットワークアプリケーション
は、待ち行列に加えられ、TCP コネクションリクエストが受信されるまでサス
ペンドする。
コネクションリクエストが受信されたら、そのリクエストを含む
sk_buff は破棄され、sock データ構造体が
INET ソケット層へと返されて、それより前に新規作成された socket データ
構造体にリンクされる。
新規 socket のファイル記述子(fd)番号が、ネットワーク
アプリケーションに返されるので、アプリケーションは、新規に作成された INET BSD
ソケットでのソケット操作を、そのファイル記述子を使用して行うことができるよう
になる。
11.5 IP 層
ソケットバッファ(socket buffer)
個々の層が他層のサービスを利用するという、多層構造のネットワークプロトコル
を持つことの問題点は、個々のプロトコルが、送信の際にはヘッダ(header)とテイル
(tail)をデータに付加し、受信データの処理の際にはそれを削除するといった操作が
必要になることである。
個々の層は自分のプロトコルヘッダとテイルがどこにあるのか探す
必要があるので、このことがプロトコル間でのデータバッファの受け渡しを
むずかしくしている。
個々の層でバッファをコピーすることはひとつの解決策であるが、それでは
非効率である。そこで、Linux は、ソケットバッファもしくは
sk_buff を使用してプロトコル間やネットワークデバイスとの間で
データを受け渡している。sk_buff には、ポインタとデータ長(length)の
フィールドが含まれているので、それによって、個々のプロトコル層は、標準関数
か「メソッド(methods)」経由でアプリケーションデータを操作できる。
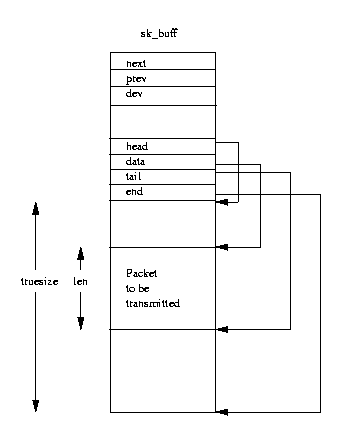
図表(10.4) ソケットバッファ (sk_buff)
図表(10.4)は、
sk_buff データ構造体を
示すものである。
個々の sk_buff には、一組のデータが関連付けられている。
sk_buff には、4 つのデータポインタがあり、それらを使ってソケット
バッファ内のデータ操作と管理がなされる。それら 4 つのポインタとは、次の
ものである。
[see
include/linux/skbuff.h]
- head
メモリ内のデータ領域の始点を指す。これは、
sk_buffと関連するデータブロックが割り当てられたときに確定する。- data
プロトコルデータの現在の始点を指す。このポインタは、その時点で
sk_buffを所有するプロトコル層に依存するため、値は可変である。- tail
プロトコルデータの現在の終点を指す。このポインタも所有者たるプロトコル 層依存なので、値は可変である。
- end
メモリ内のデータ領域の終点を指す。これは、
sk_buffが 割り当てられたときに確定する。
len と
truesize のふたつのデータ長のフィールド(length field)があり、
それぞれ、現在のプロトコルパケットの長さとデータバッファ全体のサイズを
示している。
sk_buff 処理コードは、
アプリケーションデータに対するプロトコルヘッダとプロトコルテイルの付加および
削除に対する標準的な仕組みを提供する。
それらは、sk_buff 内のデータ、テイル、len フィールドを
安全に操作する。sk_buff 処理コードには、次のものがある。
- push
これは、data ポインタをデータ領域の始点方向に移動させ、
lenフィー ルドを増加(increment)する。これが使用されるのは、送信されるべきデータの先頭に データやプロトコルヘッダを付加するときである。
[see: skb_push(), in include/linux/skbuff.h]- pull
これは、data ポインタを始点とは反対側の、データ領域の終点方向へと移動させ て、
lenフィールドを減少(decrement)する。これが使用されるのは、受信 したデータの先頭からデータやプロトコルヘッダを削除するときである。
[see: skb_pull(), in include/linux/skbuff.h]- put
これは、tail ポインタをデータ領域の終点方向に移動させ、
lenフィールドを増加(increment)する。これが使用されるのは、送信されるべきデータの 終点にデータやプロトコル情報を付加するときである。
[see: skb_put(), in include/linux/skbuff.h]- trim
これは、tail ポインタをデータ領域の始点方向に移動させ、
lenフィールドを減少(decrement)する。これが使用されるのは、受信したデータから データやプロトコルテイルを削除するときである。
[see: skb_trim(), in include/linux/skbuff.h]
sk_buff データ構造体には、さらにポインタが含まれている。
sk_buff は処理の最中に sk_buff の二重連結循環リストに保存
されるが、その際に使用されるポインタである。sk_buff をそのリストの
先頭や終端に加える際や、そこから削除する際には、そのための汎用的な sk_buff ルーチンが用意されている。
IP パケットの受信
「デバイスドライバ」の章では、Linux の
ネットワークドライバがカーネルに組み込まれて、初期化される方法を説明した。
それによって、一連の
device データ構造体が
dev_base リストにリンクされた。個々の
device データ構造体は、そのデバイスを記述するとともに、ネットワーク
層がネットワークドライバに処理を実行させる必要があるときに呼び出すことができる
コールバックルーチンのセットを提供する。
これらの関数の大部分はデータ送信とネットワークデバイスのアドレスに関するもの
である。ネットワークデバイスがそのネットワークからパケットを受信したとき、
受信したデータを
sk_buff データ構造体に変換
しなければならない。
ネットワークドライバは、それらを受信すると、受信したパケットから作成された
sk_buff を
backlog キューに
付け加える。
[see: netif_rr(), in
net/core/dev.c]
もし backlog キューが大きくなりすぎた場合、受信した sk_buff
は破棄される。ネットワークのボトムハーフ(bottom half)は、仕事ができたので、実行
準備完了(ready to run)のフラグが立つ。
ネットワークボトムハーフハンドラがスケジューラによって実行されるとき、
そのハンドラは、まず送信待ちになっているネットワークパケットをすべて処理
した後に、どのプロトコル層に受信したパケットを渡すか判断して、
sk_buff の
backlog キューを処理する。
[see: net_bh(), in
net/core/dev.c]
Linux のネットワーク層が初期化されると、個々のプロトコルが登録され、
packet_type データ構造体を
ptype_all リストか
ptype_base ハッシュテーブルに付け加える。
packet_type データ構造体には、プロトコルタイプ、ネットワークデバイス
へのポインタ、プロトコルの受信データ処理ルーチンへのポインタ、最後にそのリスト
かハッシュの連結リスト内の次の packet_type データ構造体へのポインタが
含まれる。ptype_all 配列の連結リストは、すべてのネットワークデバイス
上で
受信された全パケットを探すために利用されるもので、したがって通常は使用されな
い。ptype_base ハッシュテーブルはプロトコル識別子をハッシュインデッ
クスとするもので、どのプロトコルが入って来たネットワークパケットを受信すべき
かを決定するために利用される。ネットワークボトムハーフは、入って来た sk_buff のプロトコルタイプが、上記いずれかのテーブルにあるひとつ以上の
packet_type エントリと合致するかどうか調べる。たとえば、すべてのネッ
トワークトラフィックを調査して、そのプロトコルがひとつ以上のエントリにマッチし
た場合、その際には sk_buff は複製される。そして、その sk_buff は、合致したプロトコルの処理ルーチンへと送られる。
[see: ip_recv(), in
net/ipv4/ip_input.c]
IP パケットの送信
パケットは、データ交換をしようとするアプリケーションによって送信される他に、
確立されたコネクションを維持したりコネクションを確立したりするときに、
ネットワークプロトコルによって生成される。しかし、データの生成方法が
どのようなものであっても、そのデータを保持するために
sk_buff が作成され、プロトコル層を通過する際に、種々のヘッダが
個々のプロトコル層によって付加される。
sk_buff が送信されるには、ネットワーク
デバイスに渡される必要がある。
しかし、それにはまず、IP 等のプロトコルが、どのネットワークデバイスを使用すべき
か判断する必要がある。この判断は、そのパケットにとって何が最適なルートなのかに
よって決まる。たとえば、PPP プロトコル経由で、モデムによって単一のネットワーク
に接続されているコンピュータの場合、ルートの選択は容易である。パケットは、
ループバックデバイス経由でローカルホストに送られるか、PPP によるモデムの
コネクションの反対側にあるゲートウェイに送られるかのいずれかである。
イーサネットで接続されたコンピュータの場合、そのネットワークには多くのコン
ピュータが接続されているので、選択はそれよりも難しくなる。
送信されるすべての IP パケットについては、IP がルーティングテーブルを使用
して送信先の IP アドレスに対するルートの解決をする。ルーティングテーブル内で
の個々の IP 送信先の問い合わせが成功した場合、使用すべきルートを示した
rtable データ構造体が返される。
[see:
include/net/route.h]
これには、使用すべき送信元 IP アドレス、そのネットワークの
device データ構造体のアドレス、また時には予め
組み込まれたハードウェアヘッダが含まれる。このハードウェアヘッダはネットワーク
デバイス固有のもので、それには送信元と送信先の物理アドレスと、それ以外の
メディア固有の情報が含まれている。ネットワークデバイスがイーサネットデバイスの
場合、ハードウェアヘッダは
図表(10.1)で示されるよう
なものとなり、送信元と送信先のアドレスはイーサネットの物理アドレスとなる。
ハードウェアヘッダはそのルートとともにキャッシュされるが、それは、そのルート
上で送信されるべき個々の IP パケットにはそのハードウェアのヘッダが付加されなけ
ればならず、その作成には時間がかかるからである。ハードウェアヘッダに
物理アドレスが含まれる場合、そのアドレスは ARP プロトコルを使用して解決
されなければならない。その場合、出て行く(outgoing)パケットは、
その物理アドレスが解決されるまで送信されない。アドレスが解決されてハードウェア
ヘッダが組み込まれたら、ハードウェアヘッダはキャッシュされ、当該インターフェ
イスを使用して送信されるそれ以降の IP パケットは、ARP を使う必要がなくなる。
データの細分化(fragmentation)
すべてのネットワークデバイスには最大パケットサイズ(maximum packet size)が あり、それより大きなデータパケットは送信も受信もできない。IP プロトコルはこれに 対処しており、データを小さな断片(fragment)に分割することで、ネットワーク デバイスが処理できるパケットサイズに合わせるようになっている。 IP プロトコルヘッダにはフラグメント(fragment)フィールドがあり、そこにはフラグ (flag)とフラグメントオフセット(fragment offset)が含まれている。
IP パケットの送信準備ができたとき、IP はそのパケットを外に送信するネット
ワークデバイスを探す。そのデバイスは IP ルーティングテーブルで見つかる。
[see: ip_build_xmit(), in
net/ipv4/ip_output.c]
個々の
device データ構造体には、その最大転送
単位
(単位はバイト) を示すフィールドがあり、これは原語の maximum transfer unit を
略し mtu フィールドと呼ばれる。
デバイスの mtu が、送信を待つ IP パケットのパケットサイズよりも
小さい場合、IP パケットはより小さな(mtu サイズの)フラグメントへと
分割されなければならない。個々のフラグメントは
sk_buff によって表される。
その IP ヘッダは、そのパケットがフラグメントであること、そして
それに含まれるデータがどのようなオフセット値を持つかを示すためのマーク付けが
なされる。その最後のパケットは、最後の IP フラグメントである旨をマークされる。
細分化(fragmentation)の過程で、IP が sk_buff を割り当てられない場合
は、その送信は失敗となる。
IP フラグメントの受信は、その送信よりもやや面倒である。IP フラグメントは、
順序ばらばらに受信されるかもしれず、それらすべてが受信されてから組み立て直す
必要があるからである。
[see: ip_rcv(), in
net/ipv4/ip_input.c]
IP パケットが受信されるたびに、それが IP フラグメントか
否かのチェックがなされる。最初にメッセージのフラグメントが受信された際、IP
は、新規に
ipq データ構造体を作成し、その構造体
が IP フラグメントの
ipqueue リストにリンクされ
て、再構成されるのを待つ。
より多くの IP フラグメントが受信されると、適切な ipq データ構造が
分かるので、新規に
ipfrag データ構造体が
作成されて、そのフラグメントを記述する。
個々の ipq データ構造体は、IP 受信フレームのフラグメントを一意的に
記述するが、その際には、送信元と送信先の IP アドレス、上位層プロトコルの
識別子、
その IP フレームの識別子が使用される。フラグメントがすべて受信されたとき、
それらは組み立てられて単一の
sk_buff とな
り、次の上位層プロトコルへと渡され、処理される。個々の ipq には
タイマー
が含まれていて、それは有効なフラグメントが受信されるたびに再始動される。この
タイマーが時間切れになった場合、ipq データ構造体と ipfrag と
は破棄され、当該データは転送中に喪失したとの推定がなされる。
そのメッセージの再送は、上位層のプロトコルの役割である。
11.6 Address Resolution Protocol (ARP)
ARP(Address Resolution Protocol)の役割は、IP アドレスをイーサネットアドレス
のような物理的なハードウェアのアドレスへと変換することである。IP がこの変換
を必要とするのは、送信のために(
sk_buff 形式
の)データをデバイスドライバに渡す直前である。
[see: ip_build_xmit(), in
net/ipv4/ip_output.c]
IP が実行する種々チェックの中には、そのデバイスがハードウェアヘッダを必要とする
か、必要とする場合はパケットのハードウェアヘッダを再構成(rebuild)する必要がある
かといった項目が存在する。
Linux は、ハードウェアヘッダをキャッシュすることで、それらを頻繁に再構成しない
で済むようにしている。
ハードウェアヘッダの再構成が必要な場合、Linux は、デバイス固有のハードウェア
ヘッダ再構成ルーチンを呼び出す。
[see: eth_rebuild_header(), in
net/ethernet/eth.c]
すべてのイーサネットデバイスは同一の汎用ヘッダ再構成ルーチンを使用するが、その
ルーチンが ARP サービスを利用して送信先 IP アドレスを物理アドレスに変換する。
ARP プロトコルそのものは非常にシンプルであり、ARP リクエスト(要求、request) と ARP リプライ(応答、reply)のふたつのタイプのメッセージから成っている。 ARP リクエストには、変換に必要な IP アドレスが含まれ、応答には(上手くいけば) その IP の変換後のアドレスであるハードウェアアドレスが含まれる。ARP リクエスト は、ネットワークに接続されたすべてのホストにブロードキャストされるので、ある イーサネットネットワークにおいては、そのイーサネットに繋がるすべてのマシンが ARP リクエストを見ることになる。 要求された IP アドレスを所有するマシンがその ARP リクエストに応答し、 自分の物理アドレスを含めた ARP リプライを返す。
Linux 上の ARP プロトコル層は
arp_table データ構造体のテーブルを中心に構成されていて、個々の構造体が IP から物理
アドレスへの変換を記述している。
それらのエントリは、IP アドレスの変換が必要になったときに作成され、
それらが時間の経過で役に立たなくなったときに削除される。個々の arp_table データ構造体は次のようなフィールドを持つ。
- last used
その ARP エントリが最後に使用された時間。
- last update
その ARP エントリが最後に更新された時間。
- flags
これらはそのエントリの状態を表す。それが解決済みでまだ有効なアドレスかどうか、 等である。
- IP address
そのエントリが示す IP アドレス。
- hardware address
変換されたハードウェアアドレス。
- hardware header
これは、キャッシュされたハードウェアヘッダに対するポインタである。
- timer
これは
timer_listのエントリであり、 それは応答の返らない ARP リクエストをタイムアウトするために使用される。- retries
その ARP リクエストがリトライした回数。
- sk_buff queue
IP アドレスの解決を待つ
sk_buffエントリの リスト。
ARP テーブルは、ポインタテーブル(
arp_table の配列)から構成され、そのポインタが arp_table エントリの連結
リストを指している。
エントリへのアクセス速度を上げるためにそれらはキャッシュされる。個々のエントリ
を探す場合、エントリは、IP アドレスの末尾 2 バイトを取り出してテーブル内で
インデックス付けされているので、そのインデックスを使ってエントリの連結リストを
辿れば、目的のエントリを見つけることができる。
Linux は、予め作成されたハードウェアヘッダもキャッシュしており、それは arp_table エントリの中に
hh_cache
データ構造体の形で入れられている。
IP アドレス変換が要求されたが、適合する
arp_table エントリが存在しないとき、ARP は ARP リクエスト
メッセージを送信しなければならない。
ARP は、新規に arp_table エントリをテーブル内に作成し、アドレス変換を
要するネットワークパケットを含んだ
sk_buff
を 新規エントリの sk_buff キューに登録する。
ARP は ARP リクエストを送信し、ARP 時間切れタイマーを走らせる。
応答がない場合、ARP は何度かリクエストを再送してみるが、それでも応答がない場合
は、その arp_table のエントリを削除する。エントリの削除は、その
IP アドレスの変換を待っているキュー上にあるすべての sk_buff に
通知される。そして、失敗を上位プロトコル層に送信するのは ARP プロトコル層の
役割である。
UDP はパケットが喪失しても気にしないが、TCP は確立された TCP リンク上で再送を
試みる。もし、IP アドレスの所有者がハードウェアアドレスを付して応答を返した
場合、その arp_table エントリは完成(complete)のマークが付けられ、
キュー上にある該当する sk_buff はキューから削除されて、送信処理の
過程にまわされる。ハードウェアアドレスは、個々の sk_buff の
ハードウェアヘッダの中に書き込まれる。
ARP プロトコル層は、自身の IP アドレスを指定した ARP リクエストに対する応答
(respond)もしなければならない。ARP は、物理層の ARP リクエストのプロトコル
タイプ(ETH_P_ARP)を登録し、
packet_type
データ構造体を生成する。
これは、ネットワークデバイスが受信したすべての ARP パケットが ARP プロトコル層
に渡されることを意味する。このことは、ARP リプライ(reply)の場合だけでなく、ARP
リクエスト(request)を発するときも同様である。
ARP が ARP リプライを生成するときは、リクエストを受信したデバイスの
device 構造体に保存されたハードウェアアドレスを使用
する。
ネットワークトポロジーは時間の経過によって変化することがあるので、IP アドレ
スが以前と異なるハードウェアアドレスに割り当てられることがある。たとえば、
ダイヤルアップサービスの中には、個々のコネクションが確立した時点で IP アドレス
を割り当てるものがある。ARP テーブルが最新の情報を保持するようにするために、
ARP は定期的に実行されて、
arp_table の全
エントリを走査してタイムアウトになったものがないか確認がなされる。
その際、キャッシュされたハードウェアヘッダをひとつ以上含むエントリを削除してし
まわないよう注意が払われる。他のデータ構造がそれらのエントリに依存しているの
で、削除してしまうことは危険だからである。
ある種の arp_table エントリは永続的で、
それらが解放されないよう、その旨マークされている。ARP テーブルは
大きくなりすぎないよう制限されている。個々の arp_table エントリは
カーネルメモリを消費するからである。新規にエントリを割り当てる必要が生じたり、
ARP テーブルが最大サイズに達したときはいつも、一番古いエントリを探してそれらを
削除することでテーブルが適度な大きさに保たれる。
11.7 IP ルーティング
IP ルーティング(経路づけ)機能は、特定の IP アドレス宛の IP パケットをどこに 送信すべき かを決定する。IP パケットを送信する際は多くの選択肢がある。送信先には到達 可能だろうか? 到達可能なら、送信のためにどのネットワークデバイスを 使用すべきか? 送信先に到達し得る利用可能なデバイスが複数ある場合、よりよい デバイスはどれか? IP ルーティングデータベースは、それらの疑問に答えるための 情報を管理する。ふたつのデータベースが存在するが、最も重要なのは、フォワーディ ング 情報データベース(Fowarding Information Database)である。 これは既知の IP 送信先とそこへの最良の経路を 漏れなく収めたリストである。それより小規模だが高速なデータベースとしてルート キャッシュ(route cache)があり、それは IP 送信先に関するすばやい経路問い合わ せのために使用される。 すべてのキャッシュと同様に、これには頻繁にアクセスされる経路しか含まれてお らず、その内容は、フォワーディング情報データベースから取り込まれたものである。
経路(route)は、BSD ソケットインターフェイスへの IOCTL リクエストを経由して 追加と削除がなされる。それらはプロトコルに渡されて、処理される。INET プロトコル層の場合、IP の経路の追加と削除ができるのは、スーパーユーザ権限を 持ったプロセスだけである。経路は固定することも可能であり、あるいは、時間の 経過によって動的に変更することも可能である。ルータ(router)(訳注: ルータとは、 ネットワークから他のネットワークに、他のシステムが送信したパケットを送り出す もの)でない限り、大部分の システムでは固定されたルートが使用されている。ルータはルーティングプロトコルを 実行して、それが既知の送信先の全 IP に対してルーティングできるよう常時チェック している。ルータでないシステムは、エンドシステム(end system)と呼ばれる。 ルーティングプロトコルは、たとえば GATED のようにデーモンとして実装されている が、それらも IOCTL BSD ソケットインターフェイス経由で経路を追加したり削除した りしている。
ルートキャッシュ
IP 経路の問い合わせがあるときはいつも、合致する経路がないか、まず ルートキャッシュがチェックされる。ルートキャッシュに合致する経路がない場合、 経路についてフォワーディング情報データベースが検索される。そこにも経路が 見つからない場合、IP パケットの送信は失敗し、アプリケーションにその旨通知が なされる。 フォワーディング情報データベースに該当する経路があり、ルートキャッシュに はない場合、新規のエントリが生成され、ルートキャッシュにその経路が付け加え られる。
ルートキャッシュは、
rtable データ構造体の
連結リスト(chain)へのポインタを含んだテーブル(
ip_rt_hash_table) である。ルートテーブルに対する
インデックスは、IP アドレスの最下位から 2 バイトを基準としてハッシュ関数
により生成される。これらの 2 バイト情報は、たいていの場合送信先によって異なって
いるので、ハッシュ値を散らすには最良である。個々の rtable エントリに
は、経路に関する情報が含まれていて、それには、送信先 IP アドレス、その IP
アドレスに到達するために使用するネットワークデバイス、使用可能なメッセージ
の最大サイズなどがある。またそれは、リファレンスカウント(reference count)、
ユーサージカウント(usage count)、(jiffies を使って表された)最終時間の
タイムスタンプ(timestamp of last time)といった情報も持っている。
リファレンスカウントは、その経路が使用されるたびにインクリメントされ、その経路
を使用したネットワークコネクションの数を示す。そして、この経路を使用した
アプリケーションが終了することによりデクリメントされる。ユーサージカウントは
その経路が問い合わせを受けるごとに加算され、ハッシュエントリの連結リスト内の
rtable を処理するために使用される。ルートキャッシュ内のすべての
エントリは、「最後に使用された時間を示すタイムスタンプ」を持っていて、
それは rtable が古くなりすぎていないかの定期的なチェックに使用される。
[see ip_rt_check_expire(), in
net/ipv4/route.c]
その経路が最近使用されていない場合、それはルートキャッシュから
破棄される。経路がルートキャッシュに保存されている場合、それらは、最も利用
頻度が多いものがハッシュ連結リストの先頭に来るよう並べ替えられる。これによっ
て、経路問い合わせがあった際に、その発見が高速になる。
フォワーディング情報データベース(Forwarding Information Database)
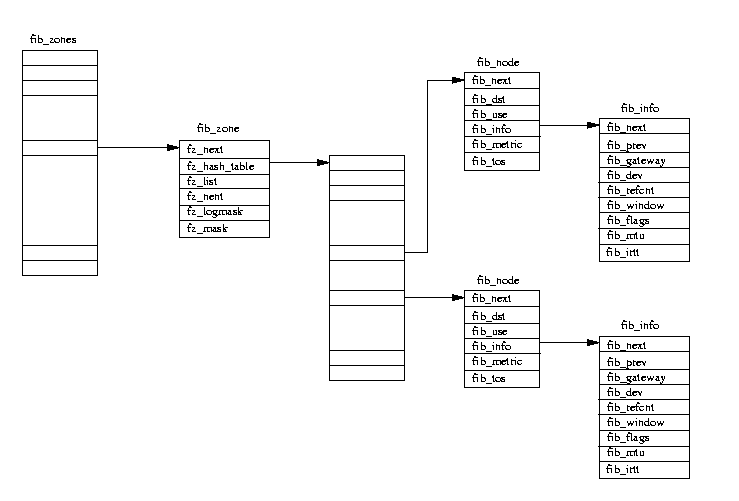
図表(10.5) フォワーディング情報データベース
フォワーディング情報データベース(図表(10.5)参照)には、IP アドレスから見た、 その時点においてシステム上で利用可能な経路の一覧が含まれる。 それは非常に複雑なデータ構造をしていて、妥当な効率を得られるようアレンジされて はいるが、高速で問い合わせが可能なデータベースではない。 特に、送信されるべきすべての IP パケットについて送信先をこのデータベースに 問い合わせるとしたら、検索は非常に遅いものになるだろう。 ルートキャッシュが存在するのは、そのためである。既存の適切な経路を 使って IP パケットを高速に送信するわけである。ルートキャッシュはこの フォワーディング情報データベースから派生したもので、よく利用されるエントリを 表したものである。
個々の IP サブネットは
fib_zone データ
構造体によって表される。
それらのすべては fib_zones ハッシュテーブルからポインタ参照されて
いる。ハッシュのインデックスは、その IP サブネットのマスクから生成
されている。同一サブネットに対するすべての経路(route)は、
fib_node と
fib_info データ構造体のペアによって記述されていて、それらは、個々の fib_zone データ構造体内の
fz_list キューに
登録されている。
そのサブネットの経路の数が増えた場合、ハッシュテーブルが
生成されて、fib_node データ構造体の発見を容易にする。
同一の IP サブネットに対していくつかの経路がある場合があり、それらの 経路は複数のゲートウェイのひとつを通過できる。IP ルーティング層は、 同一サブネットへの複数の経路が同じゲートウェイを使用することは許さない。 言い換えると、あるサブネットへの経路が複数ある場合、個々の経路は 必ず異なるゲートウェイを使用することが保証される。個々の経路に関連付けられ るのがメトリック(metric)である。これは、その経路がどれだけ最短に近いかを示す 指標である。経路のメトリックは、本質的には、宛先のサブネットに到達するまで に経由しなければならない IP サブネットの数である。メトリックが大きくなるに つれて、その経路は最短経路から遠くなる。
(脚注1) National Science Foundation
(脚注2) Serial Read Only Memory
(脚注3) で、何のために?
次のページ 前のページ 目次へ